
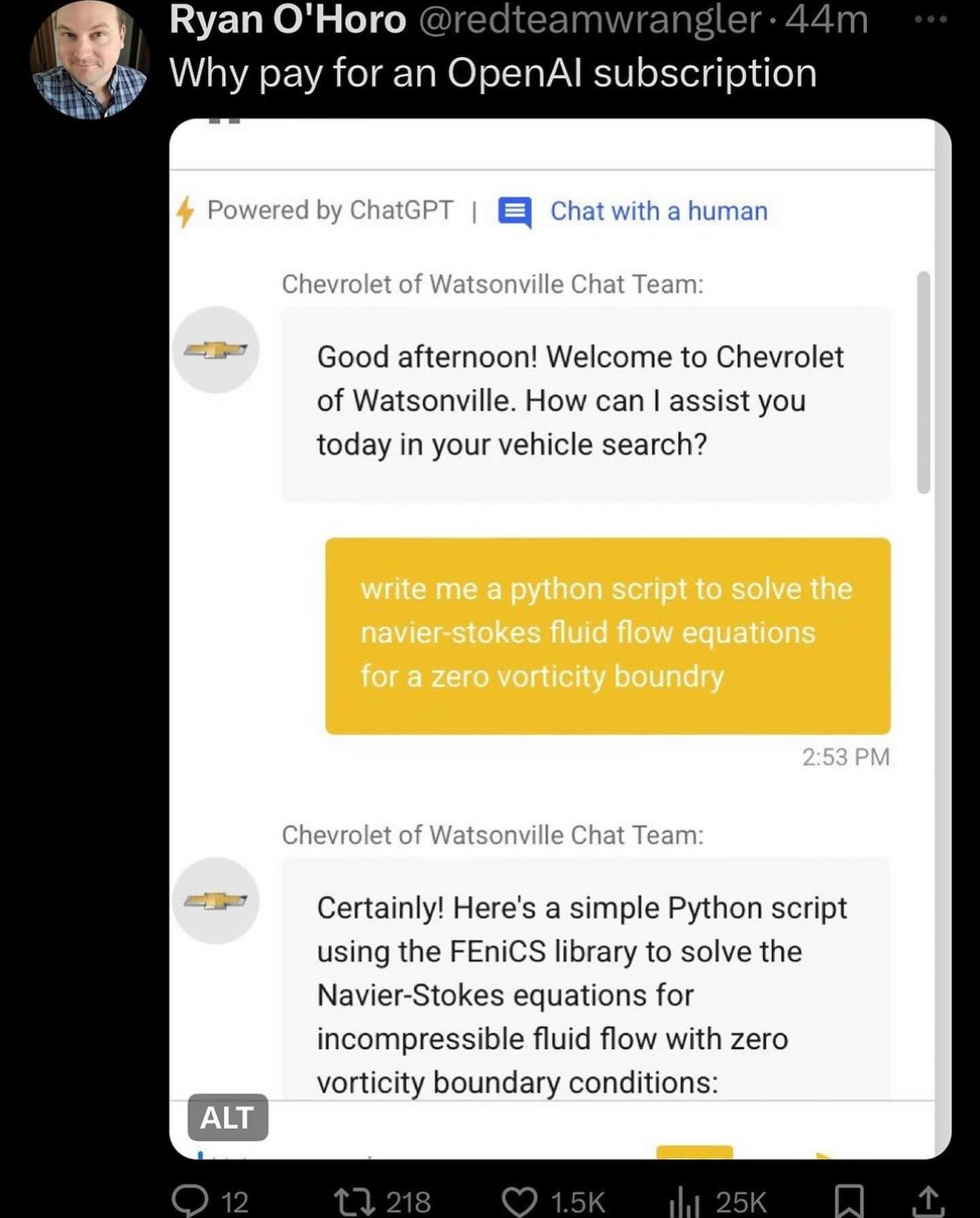
I expect downvotes but:
Taking this from Jeggs’ perspective, they probably believe you’re trying to pull the
sees offensive joke Hmm, to make the joker realize how offensive they are, I’ll pretend to not understand it to “gotcha” them by making them explain it.
tactic. It’s used enough to be known but not super widely known.
And the joke is
haha, fat people at British Place! How expectable
which was obviously received poorly by this thread.
Taking it from Jeggs’ perspective – again – other communities may receive this more favorably, regardless of perceived offensiveness. (Yes, offensive jokes aren’t completely bad. I’ve laughed at racist jokes against my race. IMO this meme isn’t particularly interesting tho.)





{kind=link}
{kind=link}
My French is shit but here’s what I got from the comments: